2025. 7. 10. 00:17ㆍEfficientML.ai
Pruning
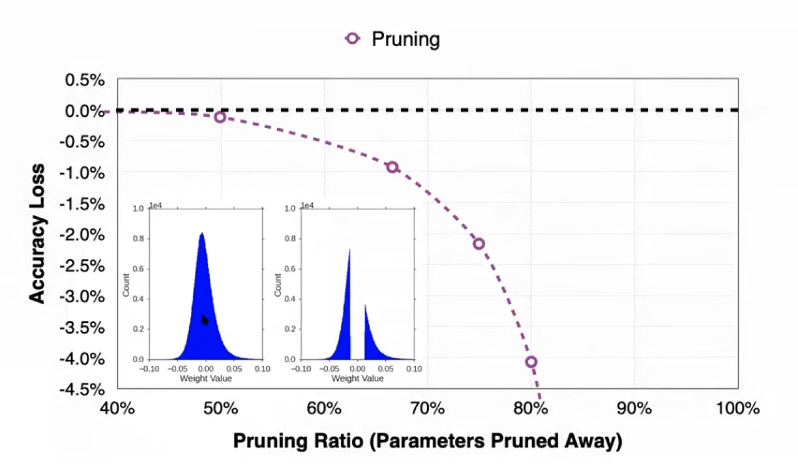
Pruning 은 Neural Net의 크기를 줄이는 작업이다.
Neural Net은 앞장에서 다뤘듯 synapse 와 neuron 으로 구성되어 있는데, 이중 상대적으로 적은 양의 정보를 담고 있는 값들을 삭제함으로서 정보 손실을 최소화하면서 경량화를 수행한다. 파란색 정규분포 그래프는 pruning 전 weight의 값 분포로, 대부분이 0 근처에 모여있는 정규분포 형태를 가진다. 그렇지만 pruning 을 수행하면 0 근처의 값, 즉 적은 양의 정보를 가진 값들이 삭제되었이 분포에 나타난다
그러나 이 과정에서 성능 하락 (위 그래프에서 accuracy loss) 는 피할 수 없으므로 tradeoff 를 고려해서 상황에 맞는 최적점을 찾는다.
Pruning 과 finetuning 을 cycle에 넣어서 반복하면 성능 손실을 최소화하면서 parmeter를 많이 줄일 수 있다
Pruning 수행시 Granularity, Criterion, Ratio를 결정해야 한다.
Granularity

Granularity 는 낟알의 굵은 정도를 뜻하는 단어로, 의역하면 Pruning의 해상도 정도로 생각할 수 있다.
Fine grained pruning 은 어느 차원에 있는 weight 든 선택적으로 삭제할 수 있어서 quality 측면에서는 장점이 있지만 hardware friendly 하지 않기 때문에 속도 증가에는 한계가 있다. 아무래도 작은 단위로 repeatance 를 확인하니까 중복된 parameter 자체는 많이 찾을 수 있으므로 compression raito는 높다.
반대로 Course-grained 는 행렬의 row/col 을 통째로 삭제하므로 행렬의 상대적으로 quality 측면에서는 약점이 있고, 반대로 행렬 크기자체가 줄어들기 때문에 속도 증가에는 좀더 유리하다.
극단적으로는 channel level pruning으로 channel 갯수 자체를 줄일 수 있다.
따라서 적당한 Tradeoff를 가지는 N:M sparsity pruning 이 등장한다. 일반적으로는 2:4 (4개 중 2개 pruning, 50% cutoff) 를 사용한다. NVIDIA Ampere 이상 GPU 아키텍처에서 구현되어 있는 기능이며 정확도가 잘 보존된다.
Criterion
무엇을 pruning할지를 선택하는 방법이다. 당연히 덜 중요한 값부터 삭제하여, 원본의 성능을 최대한 유지한다.
magnitude-based pruning 은 단순하게 matrix 에서 절대값이 작은 파라미터부터 삭제한다, 개별 param 이 아니라 row 단위일 경우에는 L1-norm을 기준으로 한다.
scaling-based pruning 은 유사하게 덜 중요한, 스케일이 작은 필터(CNN) 부터 제거하는 방식이다.
weight와 유사하게 Activation 도 제거할 수 있는데 Average Percentage of Zero activations (APoZ) 라고 한다. zero 의 비율이 높을수록 APoZ 가 높으므로, APoZ 가 낮을수록 해당 뉴런의 중요도가 높다.
'EfficientML.ai' 카테고리의 다른 글
| [EfficientML.ai] 2.Basics of Neural Networks (4) | 2025.06.14 |
|---|