2023. 11. 5. 00:45ㆍDOIK@CloudNet
- cloudnet에서 주관하는 쿠버네티스 데이터베이스 오퍼레이터 스터디 2기 내용입니다
- 목적: 다양한 db 오퍼레이터 실습으로 eks 환경에서 db 배포 및 운영을 위한 다양한 db 오퍼레이터 실습
이번주에는 Kubernates 환경에서 PostgreSQL 을 배포하고 관련 내용을 조금 정리해 보았다.
1. PostgreSQL이란?
- Cloud Native 를 잘 지원하는 오픈소스 RDBMS
- 완전한 오픈소스로서 상용 사용이 가능해 요즘 핫하게 떠오르고 있다
- 데이터베이스 계층 구조는 테이블 ⊂ 스키마 ⊂ 클러스터 로 구성된다.
- pgAdmin4라는 자체 GUI 툴을 지원해서 편리하게 사용할 수 있다.
- pg_hba.conf 를 조정해서 설정을 바꿀 수 있다.
2. CloudNativePG란?

그런 PostgreSQL을 클라우드에서 운영하기 위한 오퍼레이터로, 지난주에 소개한 오퍼레이터허브에서 무려 lv5를 달성했을 만큼 성숙한 오퍼레이터이다(참고로 오퍼레이터허브에서 lv5는 15개뿐이다). 쿠버네티스 API와 완전 연동된다는 점이 큰 장점이고 cnpg 플러그인도 지원한다. (https://operatorhub.io/)
- 가능한 서비스는 rw, ro, r 3가지가 있다. (r이 특이 사항!)
rw: read-write 요청을 primary로 전달

ro: read only 요청을 Round robin 방식으로 전달

r: 어떤 인스턴스에도 접근할 수 있다.
아래 실습에서 cnpg를 설치하고 나서 확인해보니 과연 rw에는 primary pod의 주소만, 그리고 ro에는 standby의 주소만 assign되어 있었고 r에는 모든 pod의 주소가 assign되어 있었다.

- 유연한 라이프사이클 관리를 위해 OLM(Operator Lifecycle Manager) 설치
#설치
curl -sL https://github.com/operator-framework/operator-lifecycle-manager/releases/download/v0.25.0/install.sh | bash -s v0.25.0
# namespace 확인
kubectl get ns
# olm 확인
kubectl get all -n olm
# operator 확인
kubectl get-all -n operators | grep -v packagemanifest
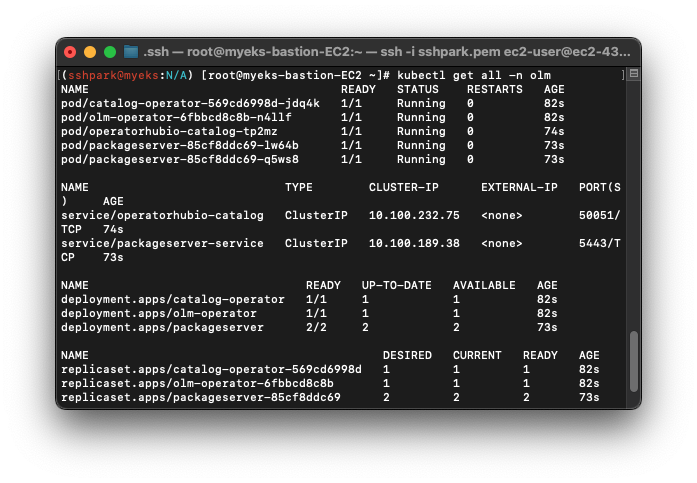

- 이제 OLM을 받았으니 오퍼레이터를 설치한다.
#Operatorhub에서 CloudNative PG 가져오기
curl -s -O https://operatorhub.io/install/cloudnative-pg.yaml
#내용 확인
cat cloudnative-pg.yaml | yh
#설치
kubectl create -f cloudnative-pg.yaml

잘 설치되었음을 확인할 수 있다.
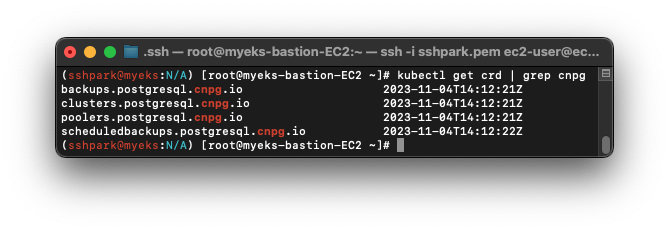
-커스텀리소스(crd)중 cnpg(CloudNativePostGresql) 플러그인을 사용하고 있는 내용들을 볼 수 있다. 위 사진에서 각각은 backup~: 백업, cluster: postgresql cluster, pooler: PGBouncer, schedulebackup: cron 에 관련된 CRD가 있음을 확인한다.
위에서 오퍼레이터를 배포했으므로 실제 클러스터를 배포해 보자
- 클러스터 배포를 위한 .yaml 내용
cat <<EOT> mycluster1.yaml
# Example of PostgreSQL cluster
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: mycluster
spec:
imageName: ghcr.io/cloudnative-pg/postgresql:15.3
instances: 3
storage:
size: 3Gi
postgresql:
parameters:
max_worker_processes: "40"
timezone: "Asia/Seoul"
pg_hba:
- host all postgres all trust
primaryUpdateStrategy: unsupervised
enableSuperuserAccess: true
bootstrap:
initdb:
database: app
encoding: UTF8
localeCType: C
localeCollate: C
owner: app
monitoring:
enablePodMonitor: true
EOT
- 순서: initdb 실행(job) -> psql pod1 Initialize -> pod1 Running -> mycluster2부터는 원래 있던 pod에 JOIN 으로 동작한다
- 생성된 pod는 PostgreSQL의 기본 포트인 :5432 외에도 :9187을 메트릭 확인용 포트로 제공한다.
-> prometheus & grafana로 시각화 가능!
# pod IP 확인
kubectl get pod -l cnpg.io/cluster=mycluster -owide
# port 9187에서 전송된 metric 확인
curl -s <파드IP>:9187/metrics
+ 클러스터 정보 확인시 --since 0m 을 추가하면 최근 액션만 확인할 수 있어 유용하다
kubectl get-all --since 5m
- krew를 활용해 cnpg 플러그인을 설치하고 이것으로 클러스터 상태를 확인할 수 있다. 사용한 이미지(postgresql 15.3), streaming sync status, instance 정보 등 유용한 정보를 한번에 확인할 수 있다.
- -verbose 옵션은 더 다양한 정보를 보여준다.
kubectl krew install cnpg
kubectl cnpg status mycluster
kubectl cnpg status mycluster -verbose
- 그리고 statefulset을 사용하지 않는다. 특히 DB처럼 민감한 대상은 statefulset 대신 custom controller 를 만들어 더 세밀하게 조정하고자 한다고. (DB에서는 치명적인) 인덱스로 접근이 안되는 것도 stateful의 단점 중 하나이다.
실제 PostgreSQL에 접속해 쿼리를 쏴보자
기본적으로 superuser(postgres), user(app) 2개가 생성되어 있다. 각각의 계정 암호를 확인하고 쓸수있게 미리 저장해놓는다.
# 계정명 확인
root@myeks-bastion-EC2 ~]# kubectl get secrets mycluster-superuser -o jsonpath={.data.username} | base64 -d ;echo
# 암호 확인
root@myeks-bastion-EC2 ~]# kubectl get secrets mycluster-superuser -o jsonpath={.data.password} | base64 -d ;echo
# app 계정 암호 지정
AUSERPW=$(kubectl get secrets mycluster-app -o jsonpath={.data.password} | base64 -d)
그리고 접근할 myclient pod를 3개 배포하고 superuser 계정으로 -rw 서비스에 접속한다
# 접근할 pod를 3개 배포한다
curl -s https://raw.githubusercontent.com/gasida/DOIK/main/5/myclient-new.yaml -o myclient.yaml
for ((i=1; i<=3; i++)); do PODNAME=myclient$i VERSION=15.3.0 envsubst < myclient.yaml | kubectl apply -f - ; done
# superuser 계정으로 mycluster-rw 접속
kubectl exec -it myclient1 -- psql -U postgres -h mycluster-rw -p 5432
하고 나면 이제 PostgreSQL 서비스를 이용할 수 있다
#접속정보 확인
\conninfo
#db 조회
\l
#...and other SQL commands
3. 복제에 대해서
- DB를 복제하는 이유는 부하분산, 고가용성, 백업이 대표적이다.
- Cloud Native PostgreSQL에서는 복제 동작의 기반으로 WAL Shipping 을 사용한다. WAL(Write Ahead Log) 은 데이터 무결성(중에서도 물리적 무결성) 을 보장하기 위한 방식이다. 사용자는 디스크에 썼다고 생각했는데 실제로는 쓰여지지 않은 상황이 대표적이다. 속도가 메모리>>>디스크 이고, 메모리와 캐시는 휘발성이기 때문에 주로 발생한다.
- 따라서 이런 상황을 해결하기 위해 말 그대로 '먼저 로그를 쓰고 데이터파일을 변경한다' 는 WAL의 개념이 도입되었다. 만약 문제가 발생해도 로그가 남아있으면 복구할 수 있기 때문이다. 로그도 없다면? 사용자는 화나겠지만 다시하면 되긴 하니까...
- Streaming Replication: WAL 파일 저장 여부와 상관없이, 메인서버 WAL이 채워질때까지 기다리지 않고 실시간으로 WAL record 를 전달한다. 다른 방식에 비해 구성이 간단하지만 메인서버를 계속 streaming 하므로 리소스를 소모한다.
- Synchronous commit: 해당 transaction의 WAL record 가 master disk 까지 write된 것을 보장한다.
- PostgreSQL은 스토리지 수준 복제 대신 애플리케이션 수준 복제를 권장한다
하면서 든 생각
- 역시 다양한 경험을 해 보는 게 중요하다: 사용해 본 DB가 스터디에서 처음으로 등장했다. 잘 알고 사용한게 아니었음에도 훨씬 따라가기 수월했다.
- 도전과제는 다른 포스트로 올려볼게요...!
References
- WAL : https://oss.tibero.com/d391cda9-ec4c-4f3c-a730-1149e7b7e4fd
10. PostgreSQL의 WAL(Write Ahead Log)
데이터베이스 관리 시스템은 데이터 무결성(Data Integrity)를 보장해야만 합니다. 다수의 데이터베이스는 데이터 무결성을 보장하기 위해 WAL(Write Ahead Log)이라는 방식을 사용합니다.
oss.tibero.com
- 복제 : https://blog.ex-em.com/1781
DB 인사이드 | PostgreSQL Replication - 종류
Replication은 Data 저장과 백업하는 방법과 관련이 있는 Data를 호스트 컴퓨터에서 다른 컴퓨터로 복사하는 것을 말한다. Replication은 RDBMS에서 추가적으로 제공하거나 여러 대의 Database Server의 부하를
blog.ex-em.com
- synchronous commit : https://minsql.com/postgres/PostgreSQL-synchronous_commit-%EA%B0%9C%EB%85%90%EB%8F%84/
PostgreSQL synchronous_commit 개념도
PostgreSQL synchronous_commit 개념도
minsql.com
'DOIK@CloudNet' 카테고리의 다른 글
| [DOIK2] 쿠버네티스 오퍼레이터 @stackable (2) | 2023.11.26 |
|---|---|
| [DOIK2] 쿠버네티스 오퍼레이터 @Kafka (0) | 2023.11.19 |
| [DOIK2] 쿠버네티스 오퍼레이터 @MongoDB (1) | 2023.11.12 |
| [DOIK2] 쿠버네티스 오퍼레이터 @MySQL (1) | 2023.10.29 |
| [DOIK2] 쿠버네티스 배포 및 기초 지식 (0) | 2023.10.22 |