[EKS@CloudNet] EKS Networking
- CloudNet에서 주관하는 EKS 스터디 2기 내용입니다
- 매번 좋은 스터디를 진행해 주시는 CloudNet 팀 감사드립니다
0. Setup
1주차와 똑같은 과정으로 CloudFormation 링크를 이용해서 셋업한다. 추가로 알려주시는 건
- 로그 확인
# check tailing
tail -f /root/create-eks.log
# see as file
vi /root/create-eks.log
- 환경변수 정보 확인
# 환경변수 확인
export | egrep 'ACCOUNT|AWS_|CLUSTER|KUBERNETES|VPC|Subnet'
# 제외하고 싶은 내용 있으면 뒤에 추가
| egrep -v 'SECRET_KEY'

하면 이런식으로 볼 수 있다. 여러사람이 같이 보는 환경이거나 하면 특히 시크릿키는 빼고 보고싶을 때니 egrep -V 를 뒤에 추가한다.
- node/pod 정보 확인

이렇게 node 3대(t3.medium) 가 배포되었고, pod은 없다.
- 그리고 실습을 편리하게 하도록 node ip 정보를 환경변수로 저장하고, 노드 보안그룹을 수정해서 노드에 접근 가능한 권한을 준다.
# 노드 IP 확인 및 PrivateIP 변수 지정
N1=$(kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2a -o jsonpath={.items[0].status.addresses[0].address})
N2=$(kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2b -o jsonpath={.items[0].status.addresses[0].address})
N3=$(kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2c -o jsonpath={.items[0].status.addresses[0].address})
echo "export N1=$N1" >> /etc/profile
echo "export N2=$N2" >> /etc/profile
echo "export N3=$N3" >> /etc/profile
echo $N1, $N2, $N3
# 노드 보안그룹에 eksctl-host 에서 노드(파드)에 접속 가능하게 룰(Rule) 추가 설정
NGSGID=$(aws ec2 describe-security-groups --filters Name=group-name,Values=*ng1* --query "SecurityGroups[*].[GroupId]" --output text)
echo "export NGSGID=$NGSGID" >> /etc/profile
aws ec2 authorize-security-group-ingress --group-id $NGSGID --protocol '-1' --cidr 192.168.1.100/32
- addon 확인: 서비스 메뉴에서 eks 검색해서 선택-> 추가기능 선택
이렇게 VPC CNI, kube-proxy, CoreDNS가 활성화되어 있다.

1. AWS VPC CNI
- CNI란: Container Network Interface로, 다양한 컨테이너 런타임이 혼용할 수 있도록 해주는 규격이다. (도커는 CNN이라는 독자규격을 사용한다)
- AWS VPC CNI의 특징은 Pod IP와 Node IP 의 대역이 같아서 서로 직접 통신이 가능하다.
+ 직접 통신뿐 이나리 성능, 지연 측면에서도 최적화되는 효과가 이있음

- 워커 노드별로 생성 가능한 최대 pod 갯수가 다르다: t3.medium 15개, c5.large 110(최대 IP 128)개
Amazon VPC CNI 플러그인으로 노드당 파드수 제한 늘리기
When a node is started in their cluster, IPAMD will allocate 2 prefixes (32 IP address) to the primary ENI (this user is not using CNI custom networking, so only the primary ENI is used in this example) to satisfy the MINIMUM_IP_TARGET of 25. Now 25 pods g
trans.yonghochoi.com
바로 위에서 AWS VPC CNI의 특장점으로 Pod IP와 Node IP 대역이 같다고 언급했는데, 그러면 이 대역으로 인해 pod 갯수가 제한되므로 AWS VPC CNI Custom Networking으로 Node-Pod 대역을 분리하면 pod 개수를 늘릴 수 있다.
EKS CNI Custom Network를 이용한 Pod 대역 분리
Today Keys : eks, cni, custom, network, pod, ip, 대역, 주소, 분리, aws, node 이번 포스팅은 EKS에서 CNI Custom Network 설정을 이용하여, node와 pod 대역을 분리를 해보는 내용입니다. 서브넷에서 활용 가능한 IP 수
zigispace.net
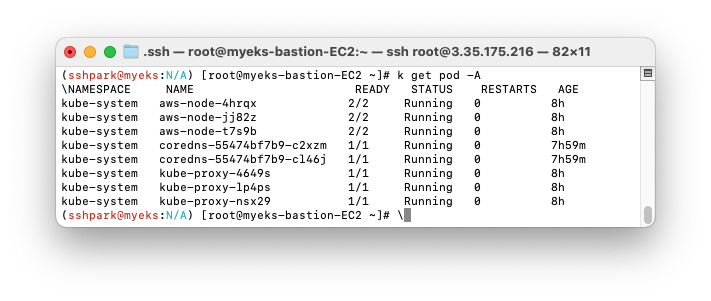
현재 총 pod는 8개이다.
+지금까진 --all-namespaces=true 를 다 쳤는데, -A로 대체할 수 있다니 이건 혁명이야

이번 실습에서는 Custom networking 이 적용되어 있어 CoreDNS의 IP와 node의 IP가 다른 것을 볼 수 있다.
2. Pod의 보조 IP 확인
총 터미널 4개가 필요하다. 각 노드를 모니터링할 터미널 3개와 command용 하나.

이때 node2 에만 랜카드가 한 장 있어서 출력이 다르다.
# terminal 1: node1 monitoring
ssh ec2-user@N1
watch -d "ip link | egrep 'eth|eni' ;echo;echo "[ROUTE TABLE]"; route -n | grep eni"
# terminal 2: node2 monitoring
ssh ec2-user@N2
watch -d "ip link | egrep 'eth|eni' ;echo;echo "[ROUTE TABLE]"; route -n | grep eni"
# terminal 3: node3 monitoring
ssh ec2-user@N3
watch -d "ip link | egrep 'eth|eni' ;echo;echo "[ROUTE TABLE]"; route -n | grep eni"
# terminal 4: commander test pod 만들기
cat <<EOF | kubectl create -f -
> apiVersion: apps/v1
> kind: Deployment
> metadata:
> name: netshoot-pod
> spec:
> replicas: 3
> selector:
> matchLabels:
> app: netshoot-pod
> template:
> metadata:
> labels:
> app: netshoot-pod
> spec:
> containers:
> - name: netshoot-pod
> image: nicolaka/netshoot
> command: ["tail"]
> args: ["-f", "/dev/null"]
> terminationGracePeriodSeconds: 0
> EOF위 화면을 설정하는 코드

- test pod를 실행하면 node2 에도 랜카드가 한장 더 할당되어서 node1, 3과 같은 상태가 되는 걸 확인할 수 있다.
노드별로 라우팅 테이블을 조회해본다.
# podname 환경변수로 내보내기
PODNAME1=$(kubectl get pod -l app=netshoot-pod -o jsonpath={.items[0].metadata.name})
PODNAME2=$(kubectl get pod -l app=netshoot-pod -o jsonpath={.items[1].metadata.name})
PODNAME3=$(kubectl get pod -l app=netshoot-pod -o jsonpath={.items[2].metadata.name})
# 라우팅 테이블 조회
for i in $N1 $N2 $N3; do echo ">> node $i <<"; ssh ec2-user@$i sudo ip -c route; echo; done

위와 같이 라우팅 테이블에서 조회 가능하다.
node3으로 접근해서 좀 더 자세히 확인해보자.
ip -br -c addr show
ip -c link
ip -c addr
ip route # 혹은 route -n네트워크 확인

- 네트워크 인터페이스 2장은 페어로 매칭되어 있다(둘다 주소 끝이 @if3으로 끝남)
sudo nsenter -t $MyPID -n ip -c addr
- nsenter(ns for namespace) 로 진입해서 확인할 수도 있다.
3. Service
Service: 클러스터 내 파드 집합에 대한 네트워크 서비스 추상화로, 3가지 종류가 있다. (node를 virtual cluster처럼 사용하게 한다~ 라고도 표현한다). "고정 진입점" 에 대한 구현이다.
ClusterIP
클러스터에 virtual ip를 만들어서, 클러스터 안의 서비스끼리 통신하도록 한다.
pod에도 IP가 있지만, pod은 언제나 내려갈 수 있으므로 신뢰할 만한 액세스 포인트로 고려하지 않는다. clusterIP는 이 문제를 해결한다.

이 그림에서 초록색 back-end와 빨간색 redis 레이어가 ClusterIP의 역할이다.
NodePort
node에서 내부 pod로의 액세스 포인트 역할을 한다.

이 그림에서 포트는 총 3개인데, 각각을 간단히 설명하면
- TargetPort: 서비스가 (최종적으로) 도착한다
- Port(service) : NodePort와 Pod를 중계한다. 이 그림에서는 Pod가 하나뿐이지만 Pod가 여러개인 경우 Service를 거쳐서 Pod로 뿌려진다.
- NodePort: Node 간의 통신을 담당한다. 이때 NodePort는 30000-32767 사이 포트번호만 허용한다.
LoadBalancer:
말 그대로 트래픽 분배로, node보다 상위에서 분배해서 pod로 트래픽을 바로 꽂아준다

(Service 이론 내용은 스터디 자료와 함께 Udemy의 CKA 강의를 참고함)
EKS Loadbalancer 실습
- OIDC(Open ID Connect)로 이기종 통신인 Loadbalancer와 EKS 사이 다리를 놔준다 (이기종 통신)
aws eks describe-cluster --name $CLUSTER_NAME --query "cluster.identity.oidc.issuer" --output text
aws iam list-open-id-connect-providers | jq
해당 정보는 aws-eks 콘솔에서도 아래 사진과 같이 동일하게 확인할 수 있다.

- 그리고 Loadbalancer controller pod에 Loadbalancer를 관리할 권한을 IAM으로 부여하고, 해당 IAM을 만든다.
(계속 조금씩 버전 업데이트 되므로, 이미 있을 시 최신버전 반영 권장)
이때 IAM을 생성하면 새 CloudFormation 스택이 생성된다.
curl -O https://raw.githubusercontent.com/kubernetes-sigs/aws-load-balancer-controller/v2.5.4/docs/install/iam_policy.json
aws iam create-policy --policy-name AWSLoadBalancerControllerIAMPolicy --policy-document file://iam_policy.json
# 이미 있다면 IAM policy 업데이트
aws iam update-policy --policy-name AWSLoadBalancerControllerIAMPolicy --policy-document file://iam_policy.json
# 생성된 policy 확인
aws iam list-policies --scope Local | jq
aws iam get-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy | jq
aws iam get-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy --query 'Policy.Arn'
# create IAM
eksctl create iamserviceaccount --cluster=$CLUSTER_NAME --namespace=kube-system --name=aws-load-balancer-controller \
--role-name AmazonEKSLoadBalancerControllerRole \
--attach-policy-arn=arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy --override-existing-serviceaccounts --approve
# check service account
kubectl get serviceaccounts -n kube-system aws-load-balancer-controller -o yaml | yh
- 그리고 pod monitoring 을 위해서 helm으로 를 loadbalancer controller를 설치한다.
helm은 k8s 생태계의 pip, npm으로 이해했다
helm repo add eks https://aws.github.io/eks-charts
helm repo update
helm install aws-load-balancer-controller eks/aws-load-balancer-controller -n kube-system --set clusterName=$CLUSTER_NAME \
--set serviceAccount.create=false --set serviceAccount.name=aws-load-balancer-controller
- 이제 service/pod 배포 테스트를 위해서 터미널을 추가하고 모니터링을 건다
watch -d kubectl get pod,svc,ep
- deployment & service 생성 pod: 이 pod을 위한 yaml 역시 가시다님이 배포해주셨다.
curl -s -O https://raw.githubusercontent.com/gasida/PKOS/main/2/echo-service-nlb.yaml
cat echo-service-nlb.yaml | yh
kubectl apply -f echo-service-nlb.yaml
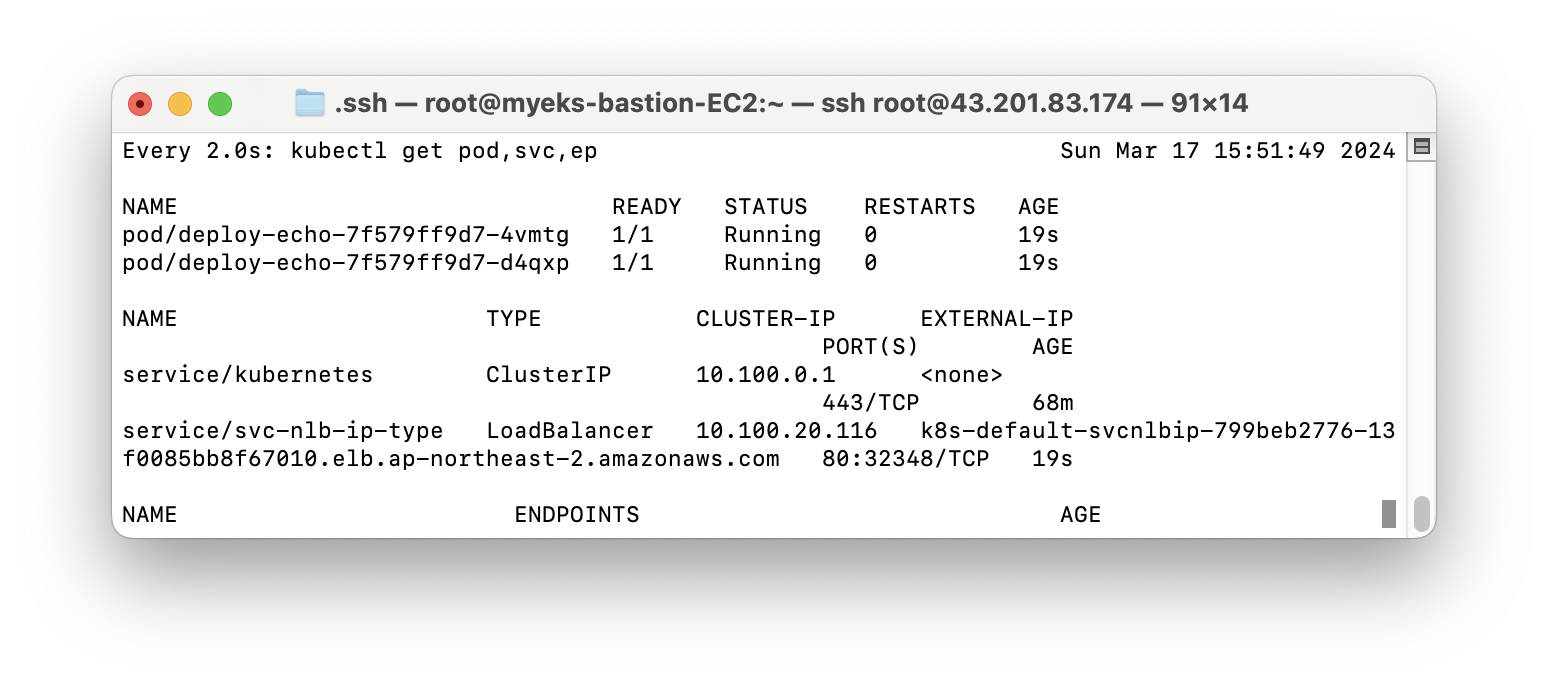
위 모니터링 터미널에 ClusterIP, LoadBalancer가 추가된 것을 볼 수 있다.
- service/loadbalancer 실습 리소스 삭제
kubectl delete deploy deploy-echo; kubectl delete svc svc-nlb-ip-type
다시 ClusterIP, LoadBalancer가 삭제된 것을 확인할 수 있다.
4. Ingress
Ingress: 클러스터 내부 서비스를 외부와 노출해서 통신이 가능하게 하는, web proxy의 역할을 해 준다.
- 서비스와 인그레스의 차이: 서비스는 클러스터 내부의 통신, 인그레스는 클러스터와 외부의 통신을 관리한다
- NodePort, ClusterIP, Loadbalancer 모두 클러스터 내부 서비스인데 이것들을 http/s 로 외부와 통신 가능하게 한다.
- aws에서는 ALB(Application Load Balancing) 서비스로 구현되어 있다.
실습
- pod 배포 : 게임 pod, service, ingress를 배포한다. 이 yaml 역시 가시다님이 배포해 주셨다.
curl -s -O https://raw.githubusercontent.com/gasida/PKOS/main/3/ingress1.yaml
cat ingress1.yaml | yh
kubectl apply -f ingress1.yaml
- 모니터링: service/loadbalancer 실습에서만 pod, svc, ep만 모니터링했지만 ingress 실습에서는 추가로 ingress, game pod를 모니터링한다. yaml로 서비스를 배포하고 나면 아래 사진과 같이 ingress, service, endpoint, game pod를 확인할 수 있다.
watch -d kubectl get pod,ingress,svc,ep -n game-2048
- ALB와 ingress의 정보를 확인할 수 있다.
# ALB 확인
aws elbv2 describe-load-balancers --query 'LoadBalancers[?contains(LoadBalancerName, `k8s-game2048`) == `true`]' | jq
# ingress 확인
kubectl describe ingress -n game-2048 ingress-2048

- ingress 주소를 조회하면 ingress를 타고 배포한 게임이 있는 pod로 들어갈 수 있다. 또한 pod을 조회하면 pod의 internal ip와 node address 도 알 수 있다.
kubectl get ingress -n game-2048 ingress-2048 -o \
jsonpath={.status.loadBalancer.ingress[0].hostname} \
| awk '{ print "Game URL = http://"$1 }'
kubectl get pod -n game-2048 -owide
게임 너무 재밌어서 한참 넋놓고 했다...
- ingress 실습 리소스 삭제
kubectl delete ingress ingress-2048 -n game-2048
kubectl delete svc service-2048 -n game-2048 && kubectl delete deploy deployment-2048 -n game-2048 && kubectl delete ns game-2048

아까 접속했던 주소로 게임에 접속할 수 없다.
!! 리소스 삭제 !!
eksctl delete cluster --name $CLUSTER_NAME && aws cloudformation delete-stack --stack-name $CLUSTER_NAME
까먹지 말아요...
여담으로 네트워크 깡통이라 이론 학습을 병행하느라 정신 없었다 ;ㅅ; 네트워크 수업 불지옥이라고 피하지 말고 들었어야 했는데...